
AIによるデータ前処理の強化
1.はじめに
保険業界では、アクチュアリーをはじめとする専門家が生データを処理し、重要なビジネス上の意思決定に役立つ幅広い分析結果を導き出している。そのため、多くの組織では、機械学習(ML)や深層学習(DL)などのAI技術によってプライシングモデルを強化する方法を積極的に研究している。しかし実際には、最も時間を消費する段階は高度なモデリングそのものではなく、データの前処理であることが多い。データの前処理とは、ユーザーの意図する目的に合わせた効果的な分析とモデリングを可能にするために、生データを精製・整理するプロセスのことである。
2.データ前処理とは
最も単純に言えば、前処理とは、データセット中の欠損値や誤って入力された値を特定し、修正することと理解できる。しかし、これはデータ前処理、具体的にはデータクリーニングの中の1つのサブプロセスに過ぎない。
Han, Kamber & Pei (2012, 3rd Ed.), Data Mining:Concepts and Techniques)によると、データ前処理は、クリーニング、統合、削減、変換、離散化を含む標準的なフレームワークとして定義されている。これらの段階は、単なるエラーの修正にとどまらず、データの品質と一貫性を確保し、モデル学習時の歪みを防ぐための重要な基盤として機能する。
3.なぜ重要なのか
データの前処理は、分析とモデリングの結果の質と信頼性に最も大きな影響を与える重要な段階である。最も洗練された方法論であっても、基礎となるデータが不完全であったり偏っていたりすれば、意味のある洞察を生み出すことはできない。構造化された前処理のフレームワークに従うことで、分析とモデリングが正確で代表的なデータに基づいて行われることが保証される。実際には、前処理作業の多くは反復的な定型作業であり、若手スタッフの時間を大幅に消費する。データを扱うスタッフに十分な専門知識がない場合、分析結果が期待に添えないこともある。
4.AIとの連携
モデリング段階(MLやDL)に比べ、AIをデータ前処理の強化に応用する研究や事例は比較的限られているが、前処理にかかる時間やコストの削減は業界共通の目標である。そのため、OCRによって文書や画像から情報を自動抽出し、データフレームに直接反映させたり、AIアシスタントを用いて列の意味を分析したり、不整合を検出したり、異常値を特定したりするためにAIを活用するケースが増えている。AIを活用した前処理技術の進展は、今後ますます重要性を増す分野である。
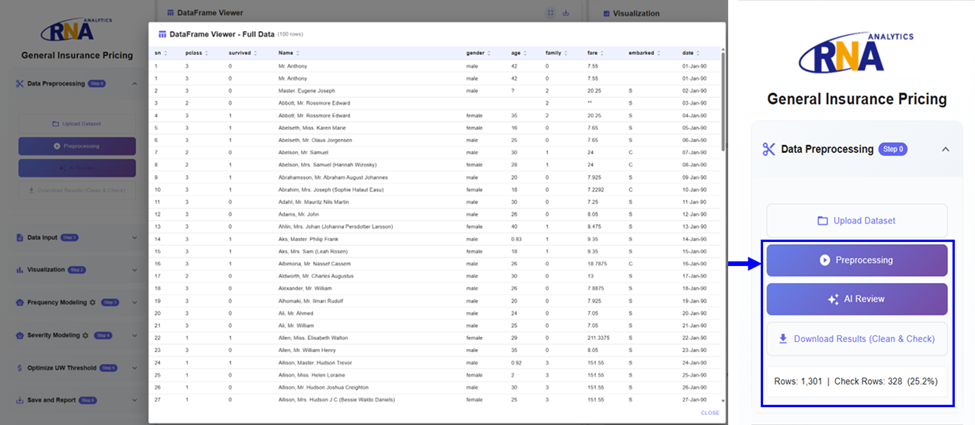
5.結論
データの前処理は、膨大な情報を扱う保険会社では特に重要である。にもかかわらず、この分野に割かれるリソースは、その重要性に見合っていない。プログラミングとAIを統合した前処理ワークフローを組み合わせることで、若手スタッフは反復的な手作業を減らし、より価値の高い分析業務に集中することができる。
今後、保険業界はAI技術とデータ前処理を組み合わせることでデジタルトランスフォーメーションを受け入れ、効率性とデータ品質の抜本的な改善を実現しなければならない。